1. 实例介绍
世界上针对大学的排名有很多种,这里我们选取由上海交通大学设计研发的最好大学排名。
我们可以在其中获得软科中国最好大学排名2019。
URL为http://zuihaodaxue.com/zuihaodaxuepaiming2019.html。
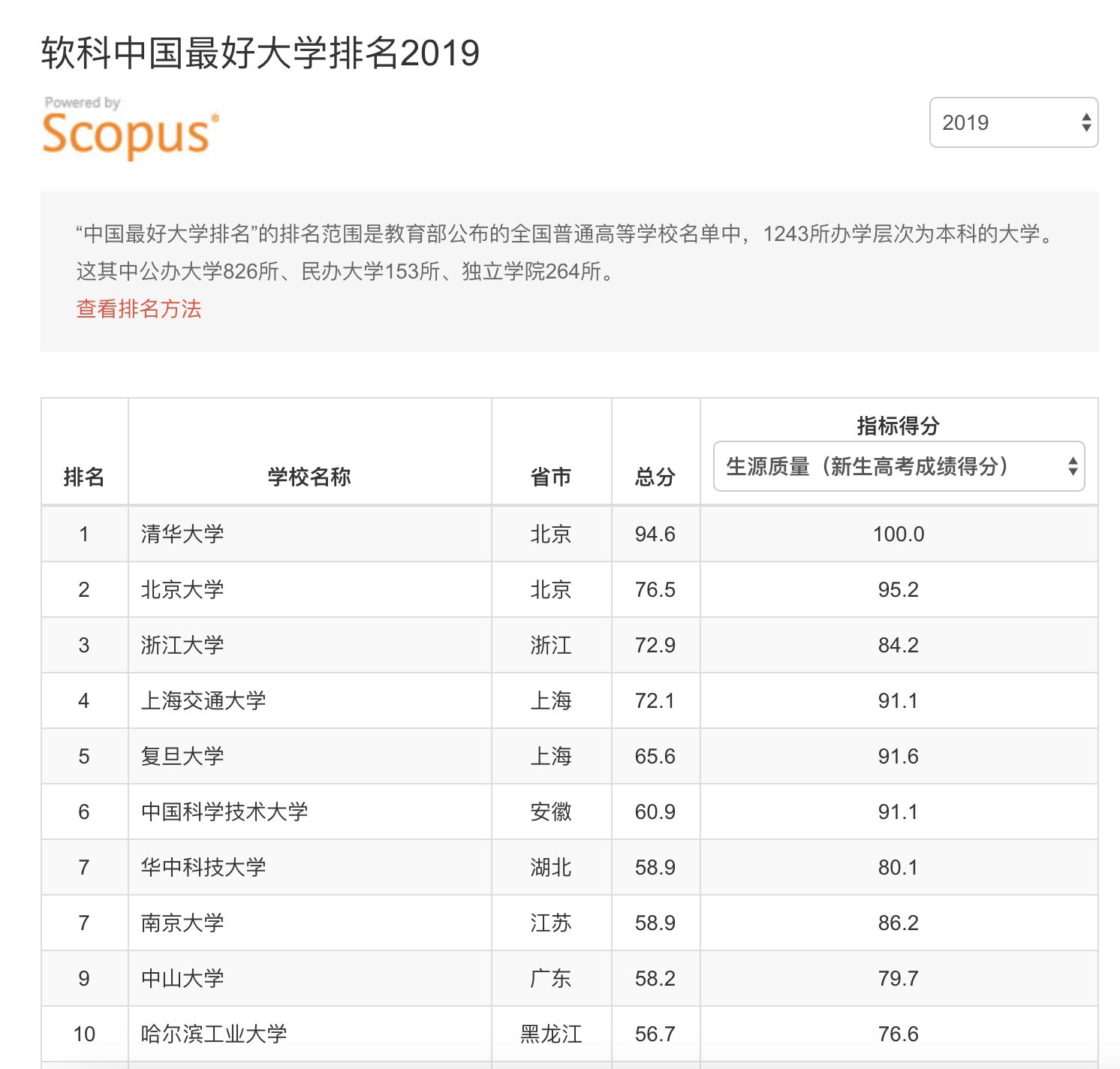
功能描述
输入:大学排名URL链接。
输出:大学排名信息的屏幕输出(排名,大学名称,总分)。
技术路线:Requests-bs4。
定向爬虫:仅对输入URL进行爬取,不扩展爬取。
在进行定向爬虫前,我们要先看看定向爬虫是否可行,也就是要爬取的信息是否在HTML代码中。
有些网站的一些信息是由JavaScript动态生成的,对于这些信息,仅靠Requests和bs4是无法实现的。
我们打开该URL,查看网页源代码,可以看到下面的内容,也就是说,我们要爬取的信息,在HTML代码中。

此外,我们查看此网站的robots协议。
打开http://zuihaodaxue.com/robots.txt ,404 Not Found,说明此网站未对爬虫限制,我们可以合法爬取。

验证可行性后,我们要对程序的结构做一个初步的设计。
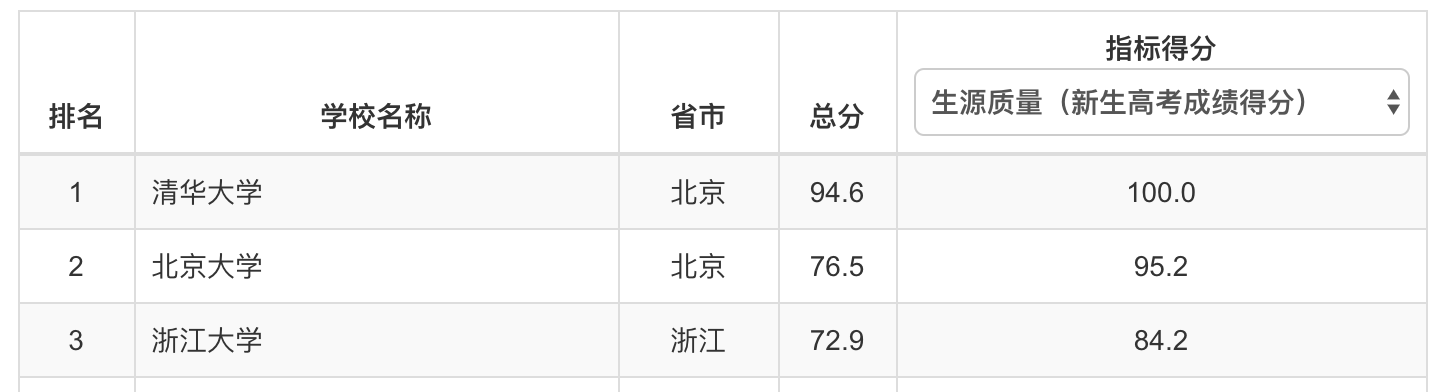
对于上面这样的信息形式,我们更适合采用一个二维列表来存储。
获取大学排名并且输出大学排名信息整个过程可以分为三个步骤。
程序的结构设计
步骤1:从网络上获取大学排名网页内容 getHTMLText()。
步骤2:提取网页内容中信息到合适的数据结构 fillUnivList()。
步骤3:利用数据结构展示并输出结果 printUnivList()。
有了这三个步骤,和三个函数,我们就可以将整个程序封装成一个模块,使程序更清晰,可读性更好。
2. 实例编写

我们在网页源代码中可以发现:
所有的大学信息都被包裹在中一对<tbody>...</tbody>标签中;
每一个大学的信息,又被包裹在一对<tr>...</tr>标签中;
一个大学信息中的每一个信息条目,又被包裹在一对<td>...</td>标签中。
有了上面的发现,程序设计中最难写的函数 fillUnivList(),也就变得很简单了。
程序代码如下,每部分代码的解释在注释中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import requests
from bs4 import BeautifulSoup
import bs4
"""
url: 待获取HTML文本的链接
返回url中的HTML文本信息
"""
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
"""
ulist: 存储大学信息的链表
html: getHTMLText()中返回的HTML文本信息
将HTML文本中的大学信息存储到ulist中
"""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.tbody.children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
"""
ulist: 存储大学信息的链表
num: 要打印的大学信息数量,前num名
打印ulist中大学排名前num的大学信息
"""
def printUnivList(ulist, num):
print("{:^6}\t{:^12}\t{:^6}".format("名次", "大学", "总分"))
for i in range(0, num):
u = ulist[i]
print("{:^6}\t{:^12}\t{:^6}".format(u[0], u[1], u[2]))
def main():
uinfo = []
url = "http://zuihaodaxue.com/zuihaodaxuepaiming2019.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 名次 大学 总分
1 清华大学 94.6
2 北京大学 76.5
3 浙江大学 72.9
4 上海交通大学 72.1
5 复旦大学 65.6
6 中国科学技术大学 60.9
7 华中科技大学 58.9
7 南京大学 58.9
9 中山大学 58.2
10 哈尔滨工业大学 56.7
11 北京航空航天大学 56.3
12 武汉大学 56.2
13 同济大学 55.7
14 西安交通大学 55.0
15 四川大学 54.4
16 北京理工大学 54.0
17 东南大学 53.6
18 南开大学 52.8
19 天津大学 52.3
20 华南理工大学 52.0
|
3. 对中英文混排输出问题进行优化
上面的输出结果存在对齐问题,虽然我们设定了打印宽度,但由于我们打印的是中文字符,而填充宽度的空格是英文字符,所以对齐的结果与我们想的不太一样。
解决方法:使用中文空格chr{12288}取代英文空格填充打印时未占满的宽度。
我们修改printUnivList()函数如下,并打印输出结果,可以看到这次的对齐效果还是不错的。
1
2
3
4
5
| def printUnivList(ulist, num):
print("{0:^6}\t{1:{3}^12}\t{2:^6}".format("名次", "大学", "总分", chr(12288)))
for i in range(0, num):
u = ulist[i]
print("{0:^6}\t{1:{3}^12}\t{2:^6}".format(u[0], u[1], u[2], chr(12288)))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 名次 大学 总分
1 清华大学 94.6
2 北京大学 76.5
3 浙江大学 72.9
4 上海交通大学 72.1
5 复旦大学 65.6
6 中国科学技术大学 60.9
7 华中科技大学 58.9
7 南京大学 58.9
9 中山大学 58.2
10 哈尔滨工业大学 56.7
11 北京航空航天大学 56.3
12 武汉大学 56.2
13 同济大学 55.7
14 西安交通大学 55.0
15 四川大学 54.4
16 北京理工大学 54.0
17 东南大学 53.6
18 南开大学 52.8
19 天津大学 52.3
20 华南理工大学 52.0
|