1. 文件结构
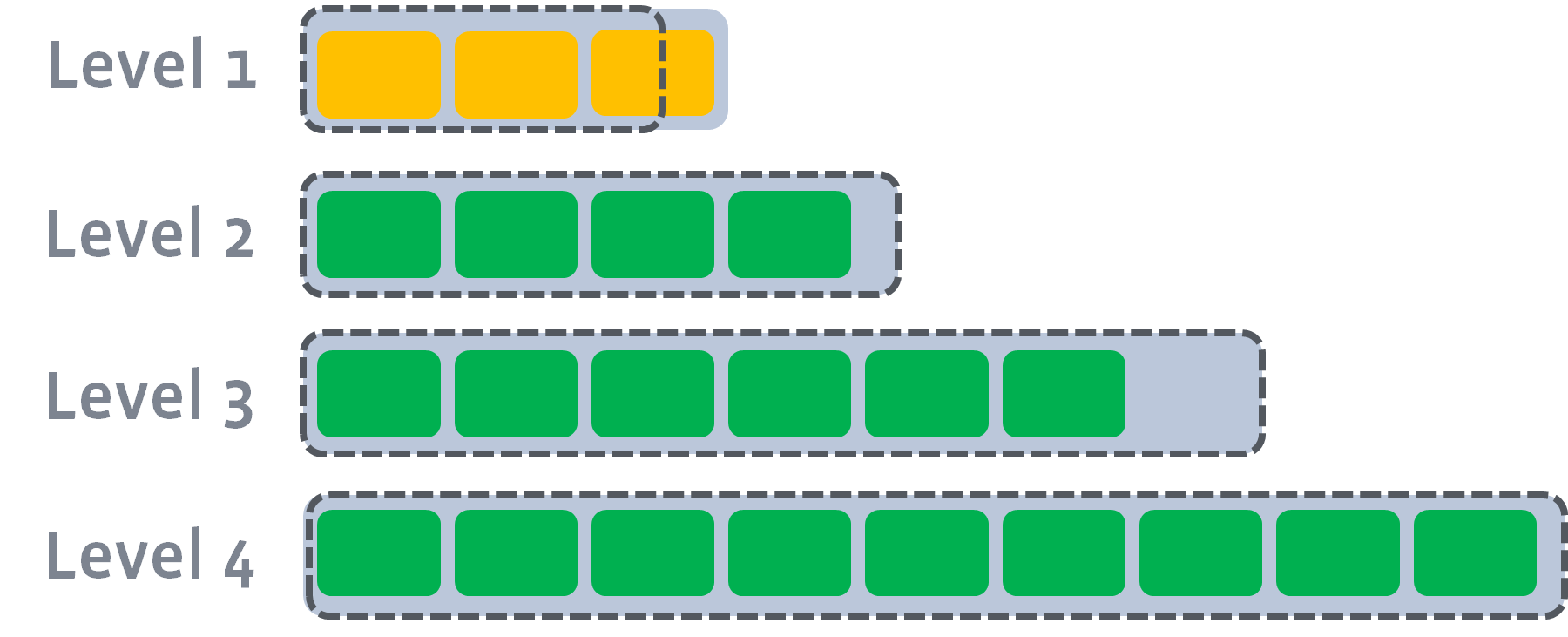
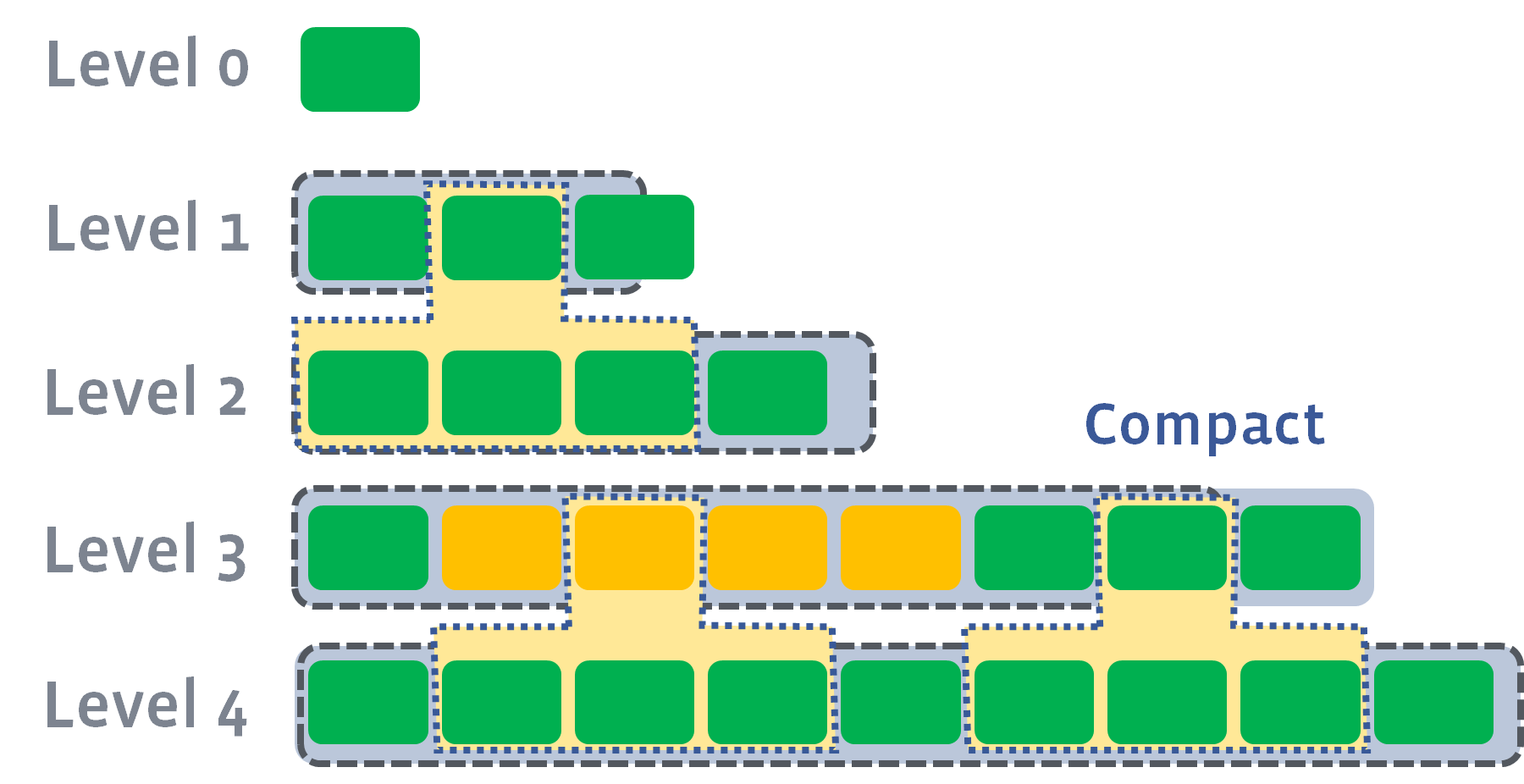
磁盘上的文件以多个级别(levels)组织。我们称它们为 level-1,level-2 等,或者 L1,L2 等。特殊的 level-0(或简称 L0)包含刚从内存中写缓冲区(memtable)flush 的文件。每个级别(除 level-0)都是一个数据排序运行(sorted run),如下:
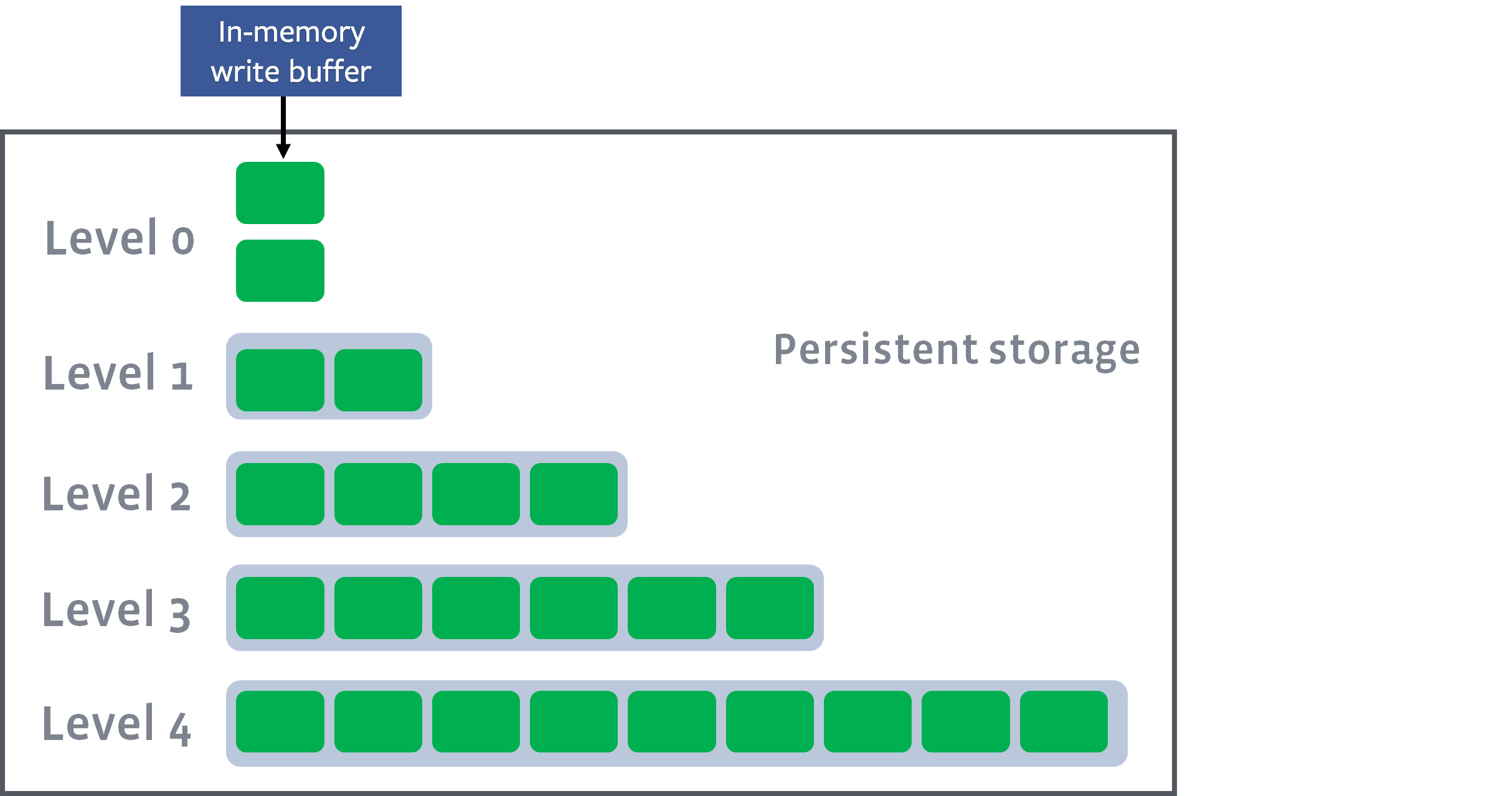
在每个级别(除级 level-0)内,数据范围分区为多个 SST 文件:
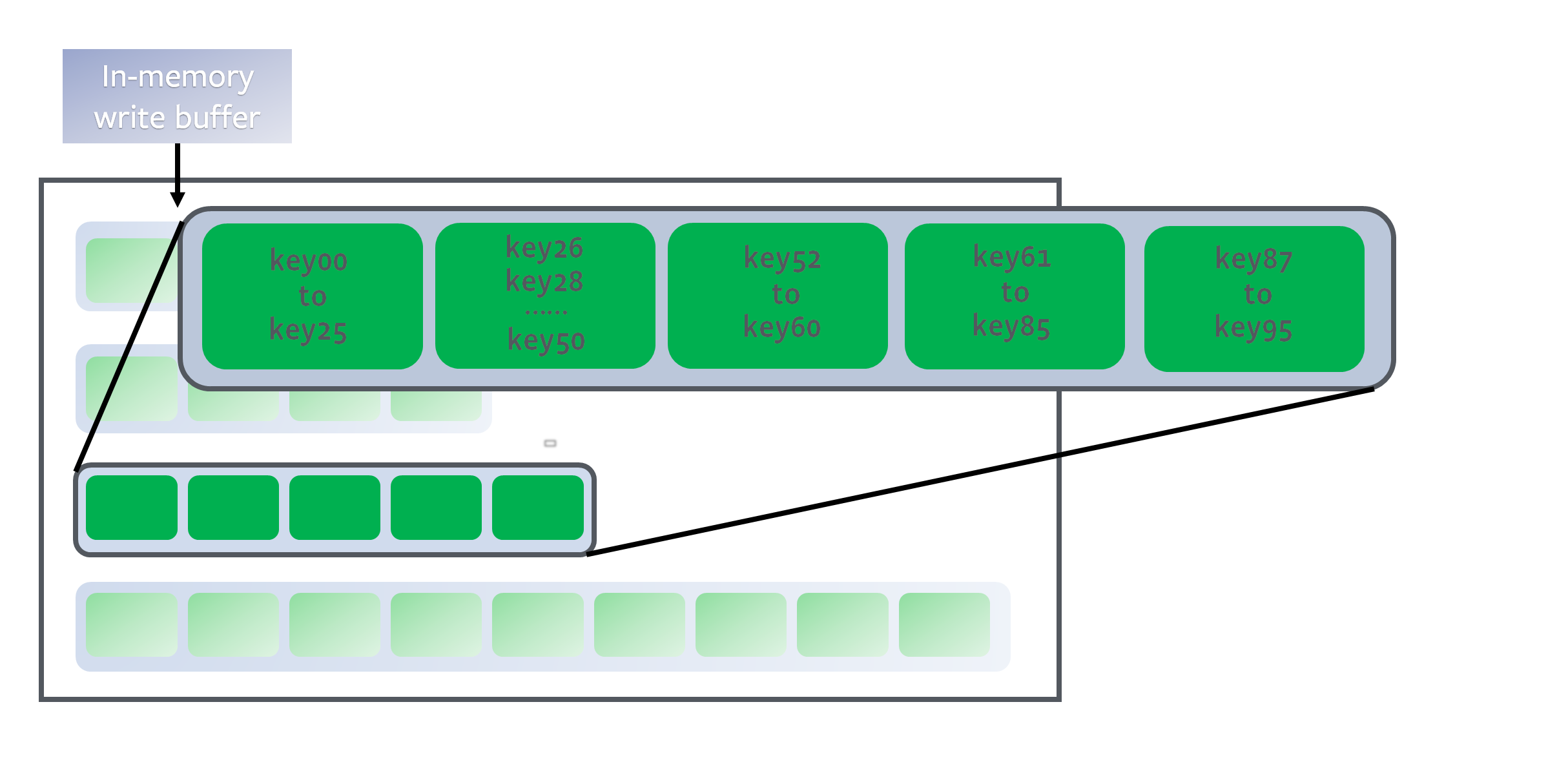
level 是排序运行,因为每个 SST 文件中的 key 都是排了序的(请参阅 Block-based Table Format 作为示例)。为了确定一个 key 的位置,我们首先对所有文件的开始/结束 key 进行二分查找,以识别哪个文件可能包含该 key,然后在文件内进行二分查找以找到确切的位置。总而言之,它是对 level 中所有 key 的二分查找。
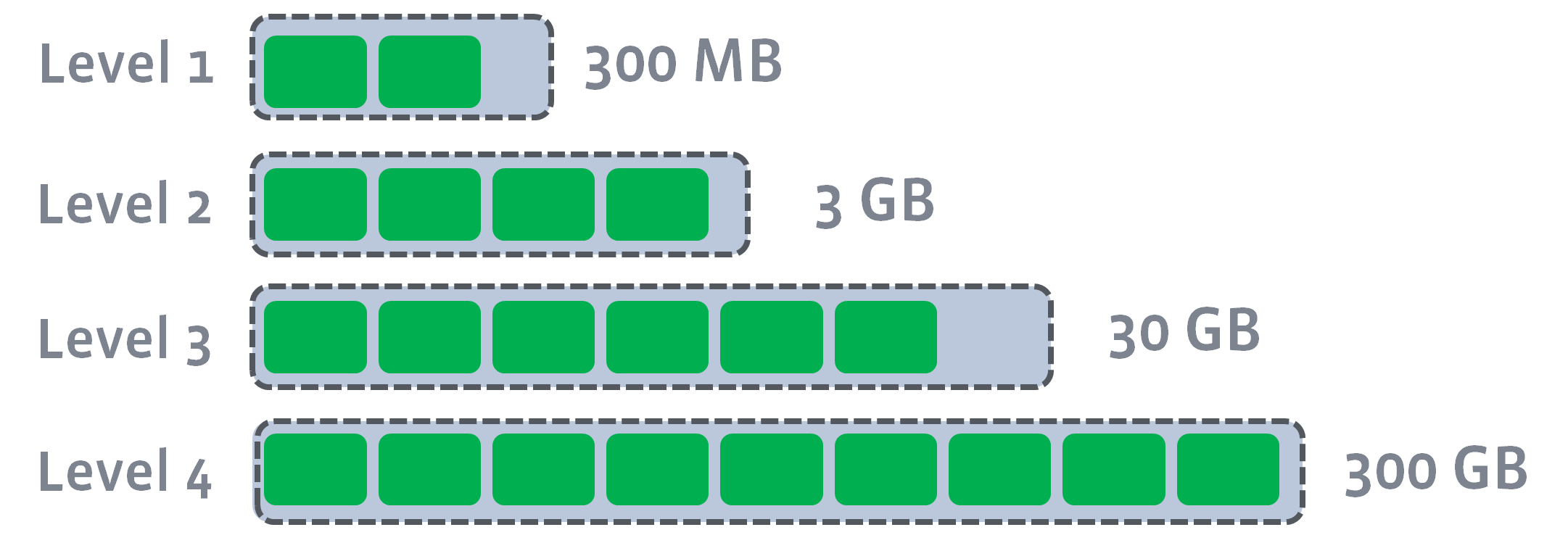
所有非 0 level 都有目标大小。Compaction 的目标是将这些 level 的数据大小限制在目标之下。目标大小通常呈指数增长:
2. 压实(Compactions)
当 L0 文件的数量到达 Level0_file_num_compaction_trigger 时,将触发压实,L0 中的文件将被合并到 L1 中。通常,我们必须选择所有L0文件,因为它们通常是重叠的:
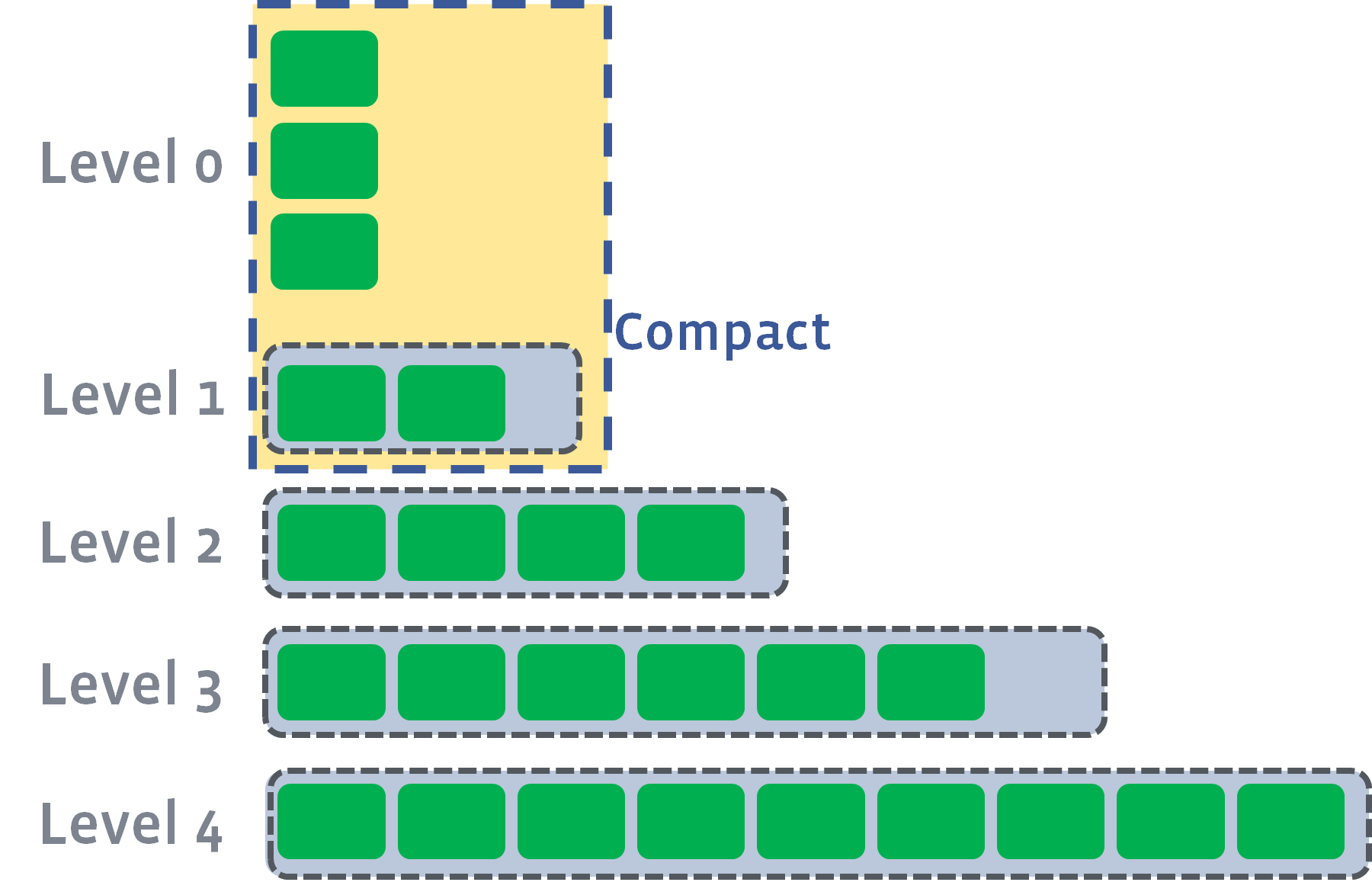
压实后,它可能会推动L1的大小超过其目标:
在这种情况下,我们将至少从 L1 选择一个文件,并将其与 L2 的重叠范围合并。结果文件将放在 L2 中:
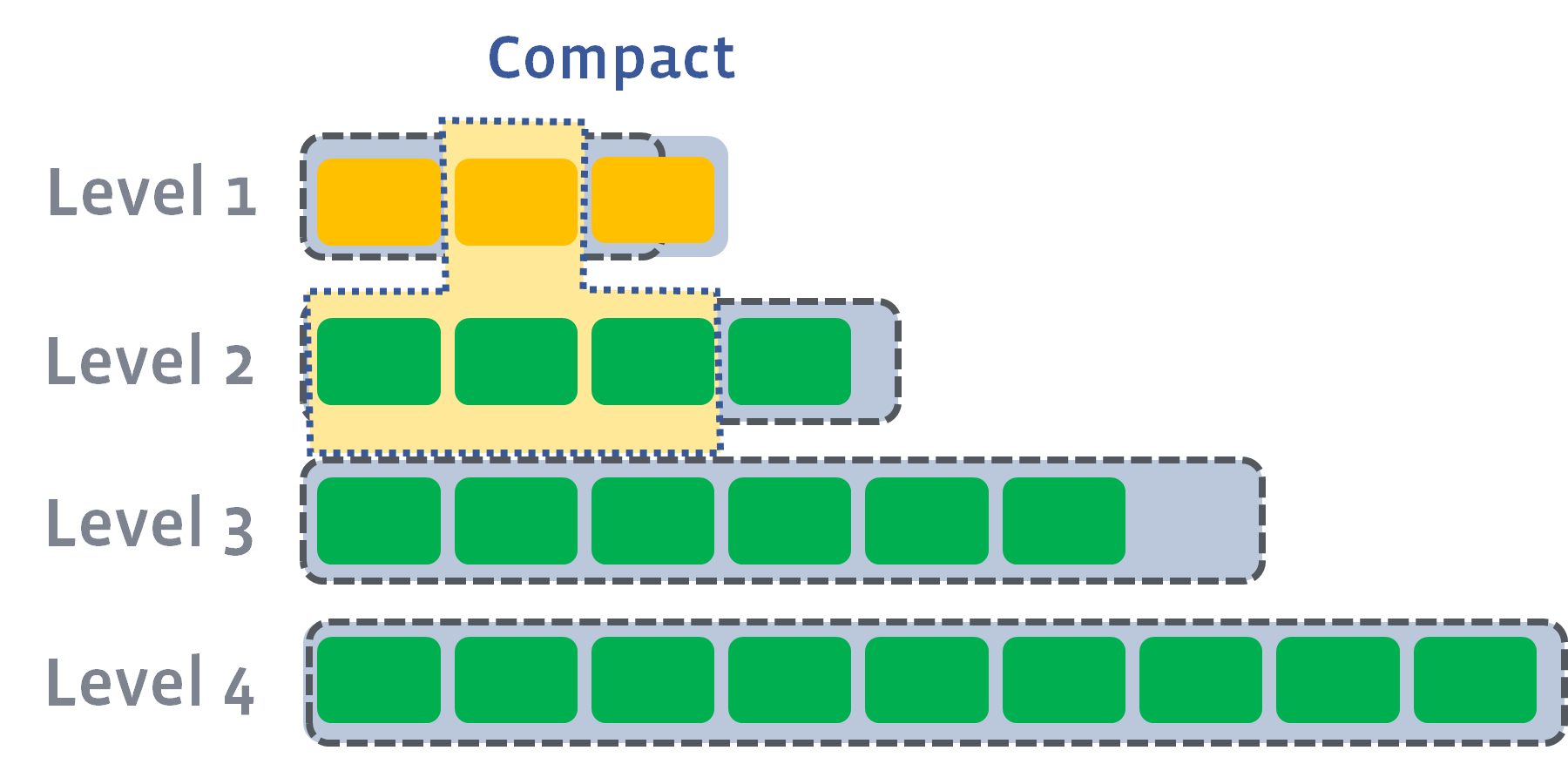
如果结果推动下一个级别的大小超过目标,我们会执行与以前相同的操作 - 拿起文件并将其合并到一个下一个级别:
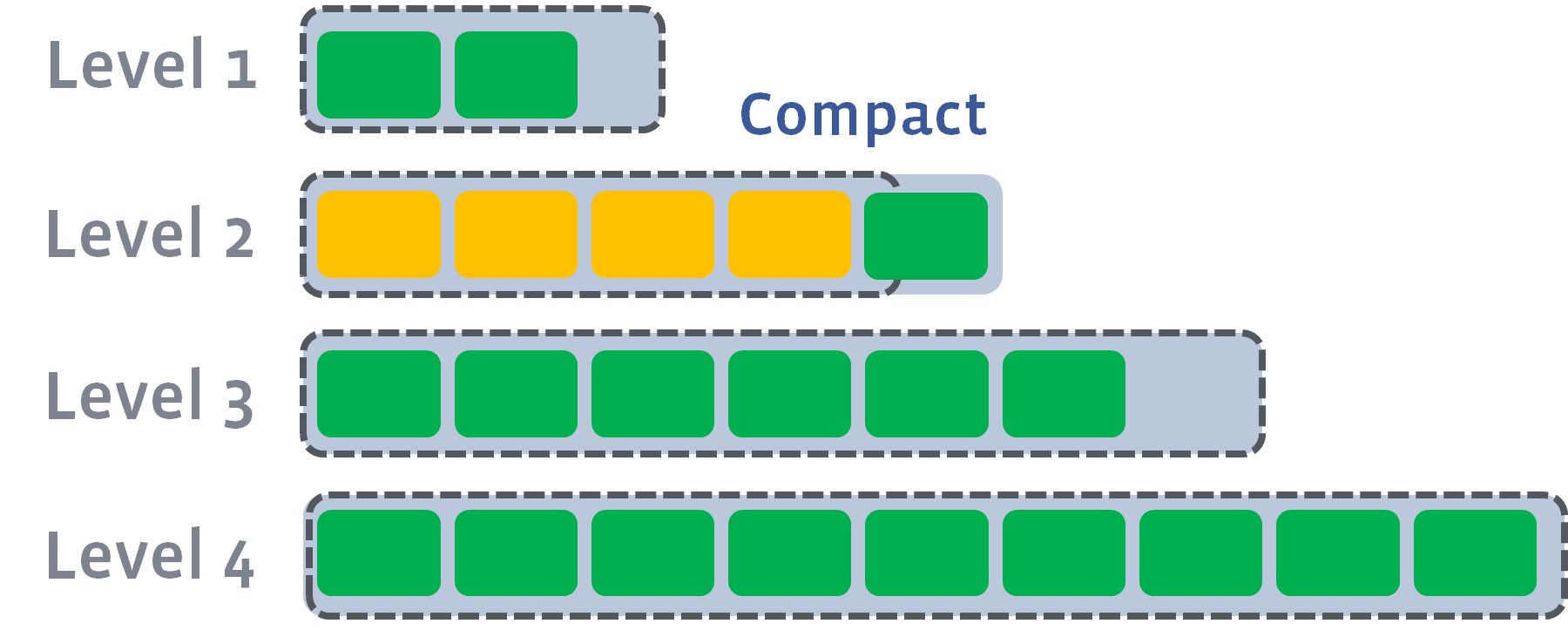
然后
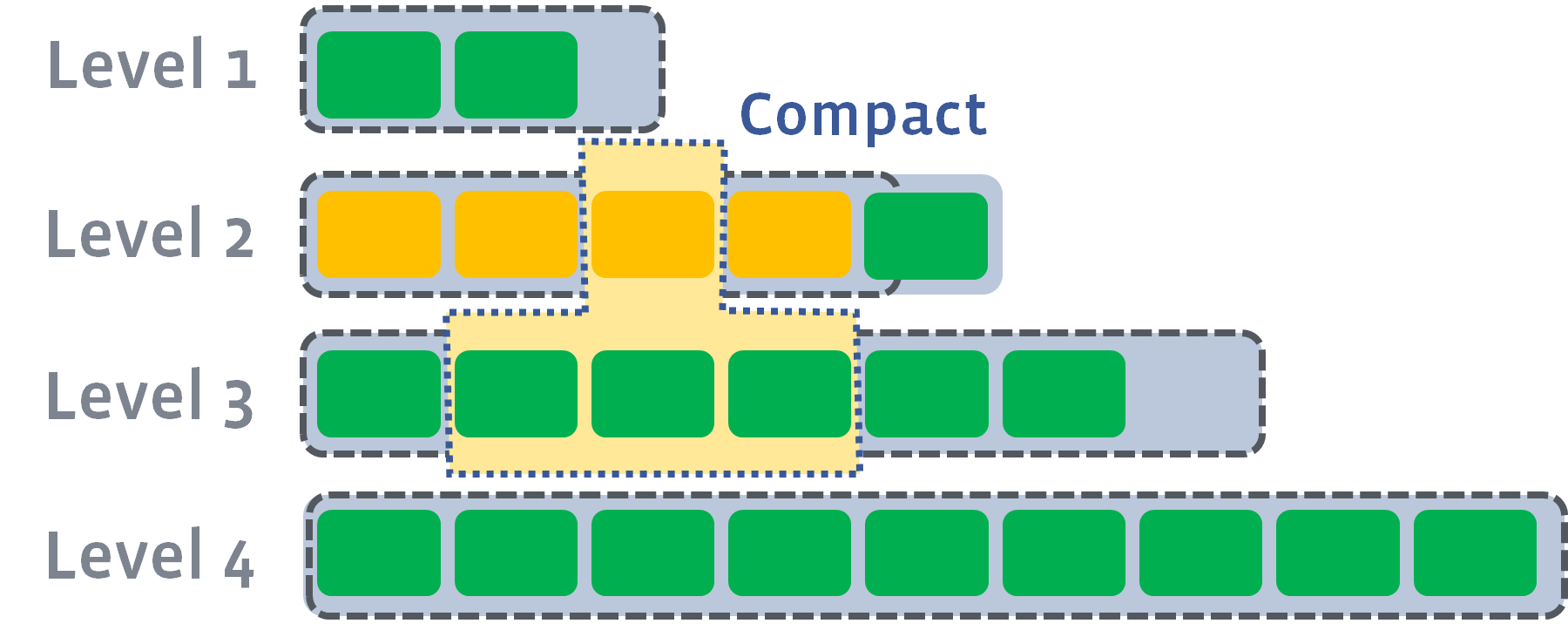
然后

如果需要,可以并行执行多个压实:
允许的最大压实数量由 max_background_compactions 控制。
但是,默认情况下 L0 至L1 的压实不是并行的。在某些情况下,它可能成为限制总压实速度的瓶颈。RocksDB 仅对 L0 至 L1 支持基于子压实(subcompaction)的并行。要启用它,用户可以将 max_subCompactions 设置为超过 1。然后,我们将尝试分区范围并使用多个线程执行它:
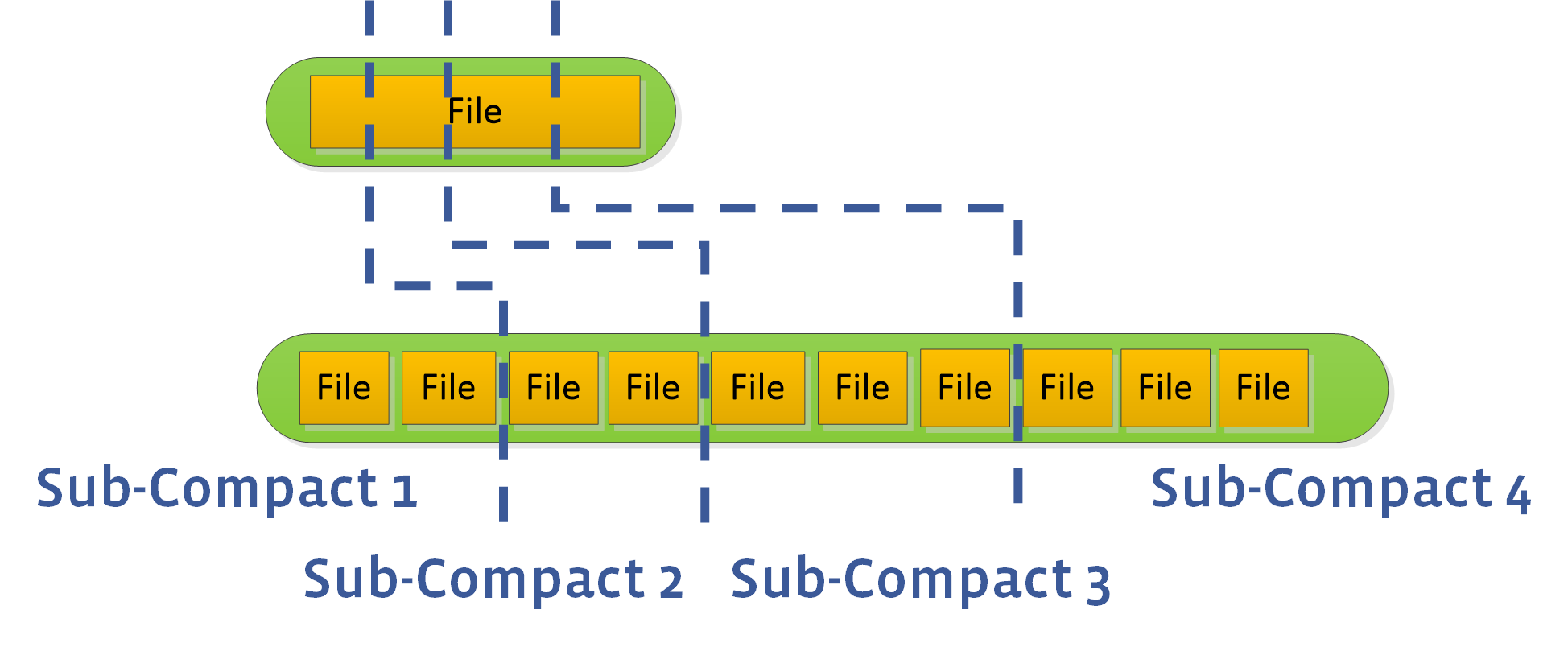
3. 选择压实
当多个 level 触发压实条件时,RockSDB 需要首先选择要压实的 level。为每个 level 生成一个分数:
- 对于非零 level,分数是该 level 的总大小除以目标大小。如果已经有被选择的文件正在被压实到下一个 level,则这些文件的大小不包括在总大小中,因为它们很快就会消失。
- 对于 level-0,分数是总的文件数量除以
level0_file_num_compaction_trigger,或者超过max_bytes_for_level_base的总大小,取较大的。(如果文件大小小于level0_file_num_compaction_trigger,则无论分数多大,都不会触发 L0 的 compact。)
我们比较每个 level 的分数,而得分最高的 level 会优先 compact。
在 Choose Level Compaction Files 中解释了哪些文件要从 level 来 compact。
4. Level 的目标大小
4.1. level_compaction_dynamic_level_bytes 为 false
如果 level_compaction_dynamic_level_bytes 为 false, level 的目标大小如下:
- L1 的目标大小是
max_bytes_for_level_base。 - Ln 的目标大小计算方法为:
Target_Size(Ln+1) = Target_Size(Ln) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[n]。max_bytes_for_level_multiplier_additional默认都是 1。
例如,如果 max_bytes_for_level_base = 16384,max_bytes_for_level_multiplier = 10,max_bytes_for_level_multiplier_additional 未设置(即全都为 1),那么 L1、L2、L3、L4 的目标大小分别为 16384、163840、1638400、16384000。
4.2. level_compaction_dynamic_level_bytes 为 true
最后一个 level(num_levels - 1) 的目标大小总是这个 level 的实际大小。然后计算之前 level 的目标,计算方法是 Target_Size(Ln-1) = Target_Size(Ln) / max_bytes_for_level_multiplier。我们不会填充其目标将低于 max_bytes_for_level_base / max_bytes_for_level_multiplier 的任何 level。这些 levels 将保持为空,所有 L0 压实将跳过这些 levels,直接进入有效目标大小的第一级。
例如,如果 max_bytes_for_level_base 为 1GB,num_levels = 6,最后一个 level 的实际大小为 276GB,则L1-L6 的目标大小为 0、0、0.276GB、2.76GB、2.76GB、27.6GB 和 276GB。
这是为了确保稳定的 LSM-TREE 结构,其中 90% 的数据存储在最后一个级别,如果level_compaction_dynamic_level_bytes 为 false,则无法保证。例如,在上一个示例中:
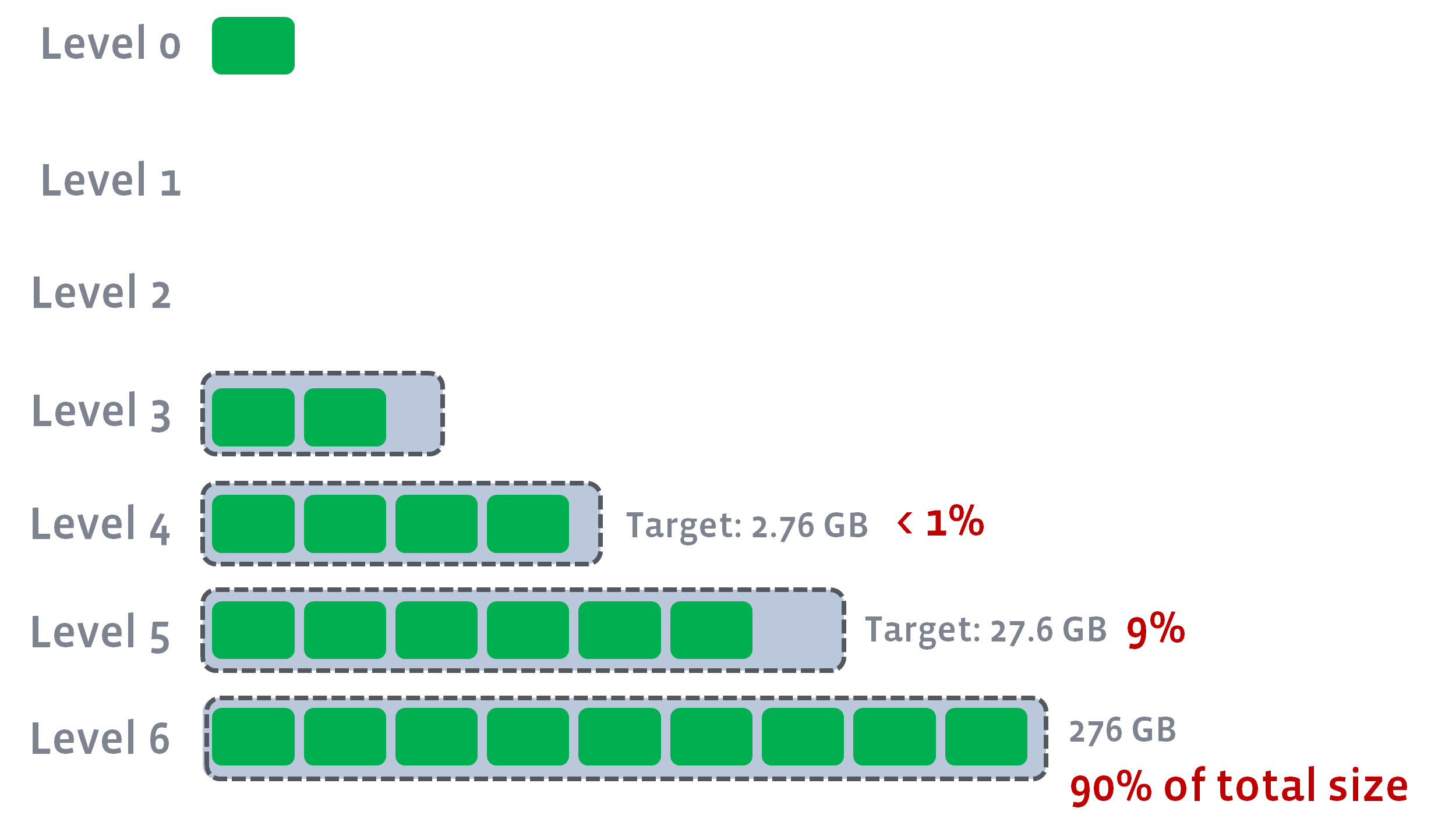
我们可以保证 90% 的数据存储在最后一个级别,第二级数据中有 9% 的数据。它将有多个好处。
4.3. 当 L0 文件堆积时
198 / 5,000
Translation results
写入任务可能有时或者一直很繁重,因此在将它们压缩到较低级别之前堆积了许多 L0 文件。 发生这种情况时,级别压实(leveled compaction)的行为会发生变化:
4.3.1. L0 内压实(Intra-L0 Compaction)
在大多数查询中,L0 文件太多损害了读取性能。为了解决该问题,RockSDB 可能会选择将某些 L0 文件压在一个更大的文件中。这牺牲了写放大,但可以显着提高 L0 中的读放大,进而增加 RocksDB 可以在 L0 中保存数据的能力。这将产生下面这些其他的好处。额外的写入放大 1 远小于通常大于 10 的 leveled compaction 的写入放大。因此,我们认为这是一个很好的权衡。L0 内压实的最大大小也由 options.max_compaction_bytes 界定。如果该选项具有合理的值,即使使用 Intra-L0 文件,总 L0 大小仍然会有界限。
4.3.2. 调整 level 的目标
如果总 L0 大小变得太大,它可能会比 L1 的目标大小更大,甚至比更低的 level 的目标大小更大。继续遵循每个 level 的配置目标是没有意义的。相反,对于动态 level,可以调整 level 的目标。 L1 的目标大小将调整为 L0 的实际大小。并且 L1 和最后一个 level 之间的所有 level 都将调整目标大小,因此级别将具有相同的乘数。其动机是使压实到较低的 level 更慢地发生。如果数据卡在 L0 -> L1 压实中,那么仍然积极压实较低级别是浪费的,这会与较高 level 的压实竞争 I/O。
例如,如果配置的乘数为 10,配置的基本 level 大小为 1GB,实际 L1 到 L4 大小分别为 640MB、6.4GB、64GB、640GB。如果出现写入高峰,将总 L0 大小推高至 10GB。L1 大小将调整为10GB,L1 到 L4 的目标大小变为 10GB、40GB、160GB、640GB。如果是最近的临时峰值,新数据可能仍停留在其当前 level L0 或下一个 level L1 中,则较低 level(即 L3、L4)的实际文件大小仍接近之前的大小,而他们的目标大小已经增加。因此较低 level 的压实几乎停止,所有资源都用于 L0 => L1 和 L1 => L2 压缩,以便它可以更快地清除 L0 文件。如果高写入率变为永久性的,调整后的目标的写放大(预期 14)比配置的(预期 32)要好,所以还是个不错的举动。
此特性的目标是为了更平滑地处理临时的写入峰值,从而进行级别压缩。请注意,级别压缩仍然无法有效地处理高于基于配置的容量的写入速率。我们正在致力于进一步改进它。
5. TTL
如果文件的 key 范围中的数据没有更新,则文件可能会在很长一段时间内不经过压实过程而存在于 LSM 树中。例如,在某些用例中,key 是“软删除(soft deleted)”的 — 将值设置为空而不是实际发出删除。可能不会再对这个“已删除”的 key 范围进行任何写入,如果是这样,这些数据可能会在 LSM 中保留很长时间,从而导致空间浪费。
已引入动态 ttl 列族选项来解决此问题。当没有其他后台工作时,将安排比 TTL 更早的文件(以及相应的数据)进行压实。这将使数据经过常规的压实过程,达到最底层并摆脱旧的不需要的数据。这也具有(良好的)副作用,即非最底层的所有数据都比 ttl 新,而最底层的所有数据都比 ttl 旧。请注意,这可能会导致更多的写入,因为 RocksDB 会安排更多的压实。
6. 定期压实
如果存在压实过滤器,RocksDB 会确保数据在一定时间后通过压实过滤器。这是通过 options.periodic_compaction_seconds 实现的。将其设置为 0 将禁用此功能。将其保留为默认值,即 UINT64_MAX - 1,表示 RocksDB 控制该功能。目前,RocksDB 会将值更改为 30 天。每当 RocksDB 尝试选择压实时,超过 30 天的文件将有资格进行压实并被压实到相同的级别。