1. JuiceFS 是什么
1.1. 简介
JuiceFS 是一款面向云原生设计的分布式文件系统。
JuiceFS 是开源的,开源协议为 Apache 2.0,开源在 GitHub 上。
JuiceFS 提供完备的 POSIX 兼容性,可以将几乎所有的对象存储接入本地作为几乎无限容量的本地磁盘使用。
JuiceFS 也可以同时挂载到不同平台、不同地区的不同主机上进行读写。
JuiceFS 采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。文件数据本身会被切分并保存在对象存储(例如 Amazon S3、阿里云 OSS 等),而元数据则可以保存在多种数据库中(例如 Redis、MySQL、TiKV、SQLite 等),用户可以根据场景与性能要求进行选择。
JuiceFS 提供了丰富的 API,适用于各种类型数据的管理、分析、归档、备份。
JuiceFS 可以在不修改代码的前提下无缝对接大数据、机器学习、人工智能等应用平台,提供海量、弹性、低价的高性能存储。
JuiceFS 的运维人员无需为可用性、灾难恢复、监控、扩容等工作烦恼,专注于业务开发,提升研发效率。JuiceFS 的运维非常简单,对 DevOps 非常友好。
1.2. 核心特性
JuiceFS 官网给出了以下核心特性:
- POSIX 兼容:像本地文件系统一样使用,无缝对接已有应用,无业务侵入性。
- HDFS 兼容:完整兼容 HDFS API,提供更强的元数据性能。
- S3 兼容:提供 S3 网关 实现 S3 协议兼容的访问接口。
- 云原生:通过 Kubernetes CSI 驱动 轻松地在 Kubernetes 中使用 JuiceFS。
- 分布式设计:同一文件系统可在上千台服务器同时挂载,高性能并发读写,共享数据。
- 强一致性:确认的文件修改会在所有服务器上立即可见,保证强一致性。
- 强悍性能:毫秒级延迟,近乎无限的吞吐量(取决于对象存储规模)。
- 数据安全:支持传输中加密(encryption in transit)和静态加密(encryption at rest)。
- 文件锁:支持 BSD 锁(flock)和 POSIX 锁(fcntl)。
- 数据压缩:支持 LZ4 和 Zstandard 压缩算法,节省存储空间。
1.3. 应用场景
JuiceFS 为海量数据存储设计,可以作为很多分布式文件系统和网络文件系统的替代,
特别是以下场景:
- 大数据分析
- JuiceFS 与 HDFS 兼容,可以与主流计算引擎(Spark、Presto、Hive 等)无缝衔接。
- JuiceFS 有无限扩展的存储空间。
- JuiceFS 的运维成本几乎为 0。
- JuiceFS 的性能远好于直接对接对象存储。
- 机器学习
- JuiceFS 与 POSIX 兼容,可以支持所有机器学习、深度学习框架。
- JuiceFS 方便的文件共享还能提升团队管理、使用数据效率。
- Kubernetes
- JuiceFS 支持 Kubernetes CSI,为容器提供解耦的文件存储。
- JuiceFS 令应用服务可以无状态化。
- JuiceFS 可以方便地在容器间共享数据。
- 共享工作区
- JuiceFS 可以在任意主机挂载。
- JuiceFS 没有客户端并发读写限制。
- JuiceFS 兼容 POSIX,即兼容已有的数据流和脚本操作。
- 数据备份
- JuiceFS 可以在无限平滑扩展的存储空间备份各种数据。
- JuiceFS 结合共享挂载功能,可以将多主机数据汇总至一处,做统一备份。
2. JuiceFS 的技术架构
JuiceFS 的技术架构图如下:
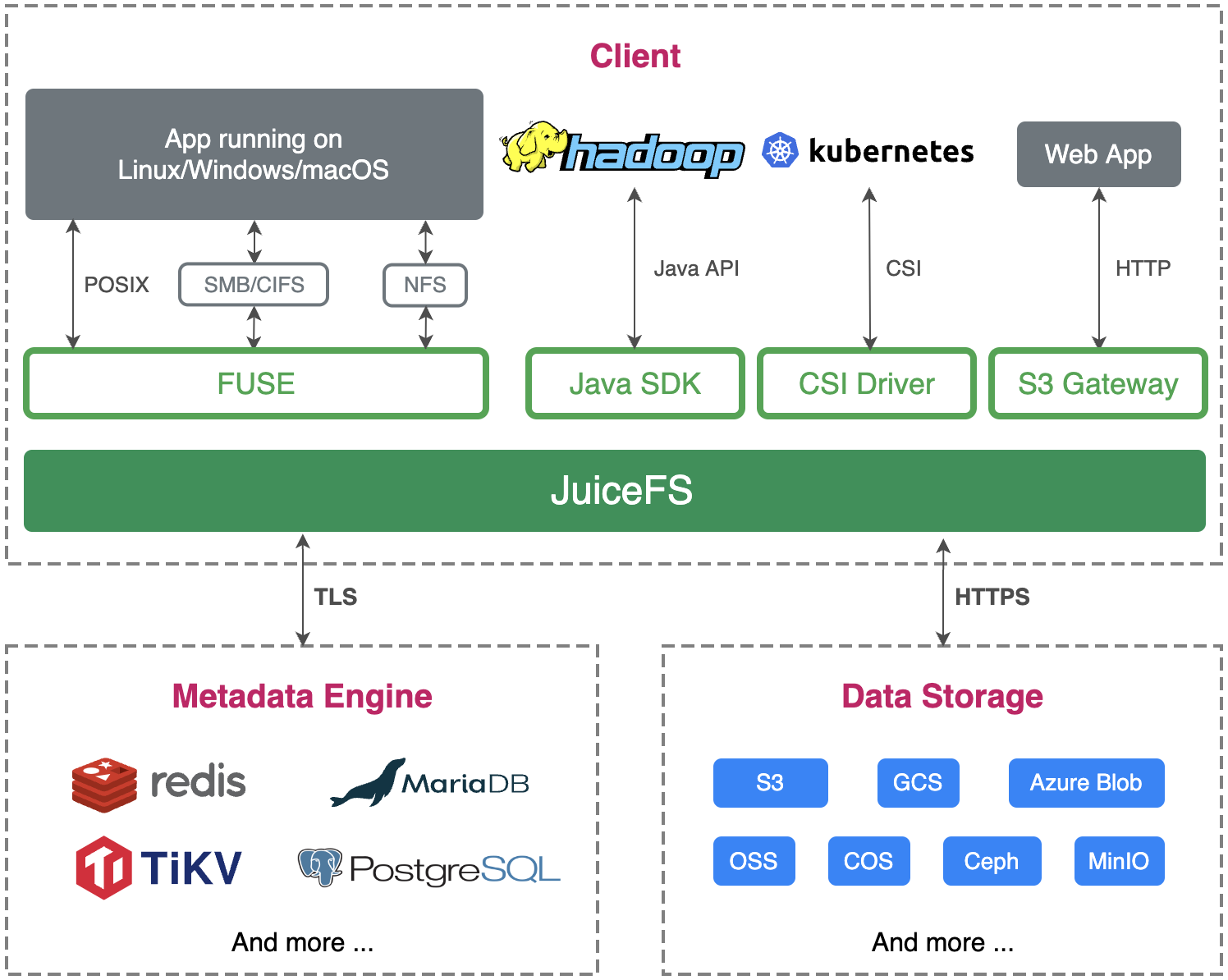
可以看到,JuiceFS 的架构上主要分为三个部分:客户端(Client)、元数据引擎(Metadata Engine) 和 数据存储(Data Storage)。
客户端(Client):所有的文件读写,包括碎片合并、回收站文件过期删除等后台任务,均在客户端中发生。客户端同时与对象存储(即数据存储)和元数据引擎打交道。客户端支持多种接入方式:
FUSE:JuiceFS 与 POSIX 兼容,可以挂载到服务器,将海量云端存储直接当做本地存储来使用。
Hadoop Java SDK:JuiceFS 能够直接替代 HDFS,为 Hadoop 提供低成本的海量存储。
Kubernetes CSI 驱动:JuiceFS 能够直接为 Kubernetes 提供海量存储。
S3 网关:使用 S3 作为存储层的应用可直接接入,同时可使用 AWS CLI、s3cmd、MinIO client 等工具访问 JuiceFS 文件系统。
WebDAV 服务:使用 HTTP 协议,以类似 RESTful API 的方式接入 JuiceFS 并直接操作其中的文件。
数据存储(Data Storage):JuiceFS 会将文件切分后上传并保存在对象存储服务中。JuiceFS 既可以使用公有云提供的对象存储服务,也可以接入私有部署的自建对象存储服务。JuiceFS 支持几乎所有的公有云上的对象存储,同时也支持 OpenStack Swift、Ceph、MinIO 等私有化的对象存储。
元数据引擎(Metadata Engine):用于存储文件元数据(metadata)。JuiceFS 采用多引擎设计,目前已支持 Redis、TiKV、MySQL/MariaDB、PostgreSQL、SQLite 等作为元数据服务引擎,也将陆续实现更多元数据存储引擎。
元数据包含以下内容:
常规文件系统的元数据,如文件名、文件大小、权限信息、创建修改时间、目录结构、文件属性、符号链接、文件锁等。
JuiceFS 独有的元数据,如文件的 Chunk 和 Slice 的映射关系、客户端 Session 等。
3. JuiceFS 存储文件的方式
传统的文件系统将数据和对应的元数据存储在本地磁盘,而 JuiceFS 则是将数据格式化以后存储在对象存储(云存储),将文件的元数据存储在专门的元数据服务中,这样的架构让 JuiceFS 成为一个强一致性的高性能分布式文件系统。
具体而言,JuiceFS 的文件存储方式如图:
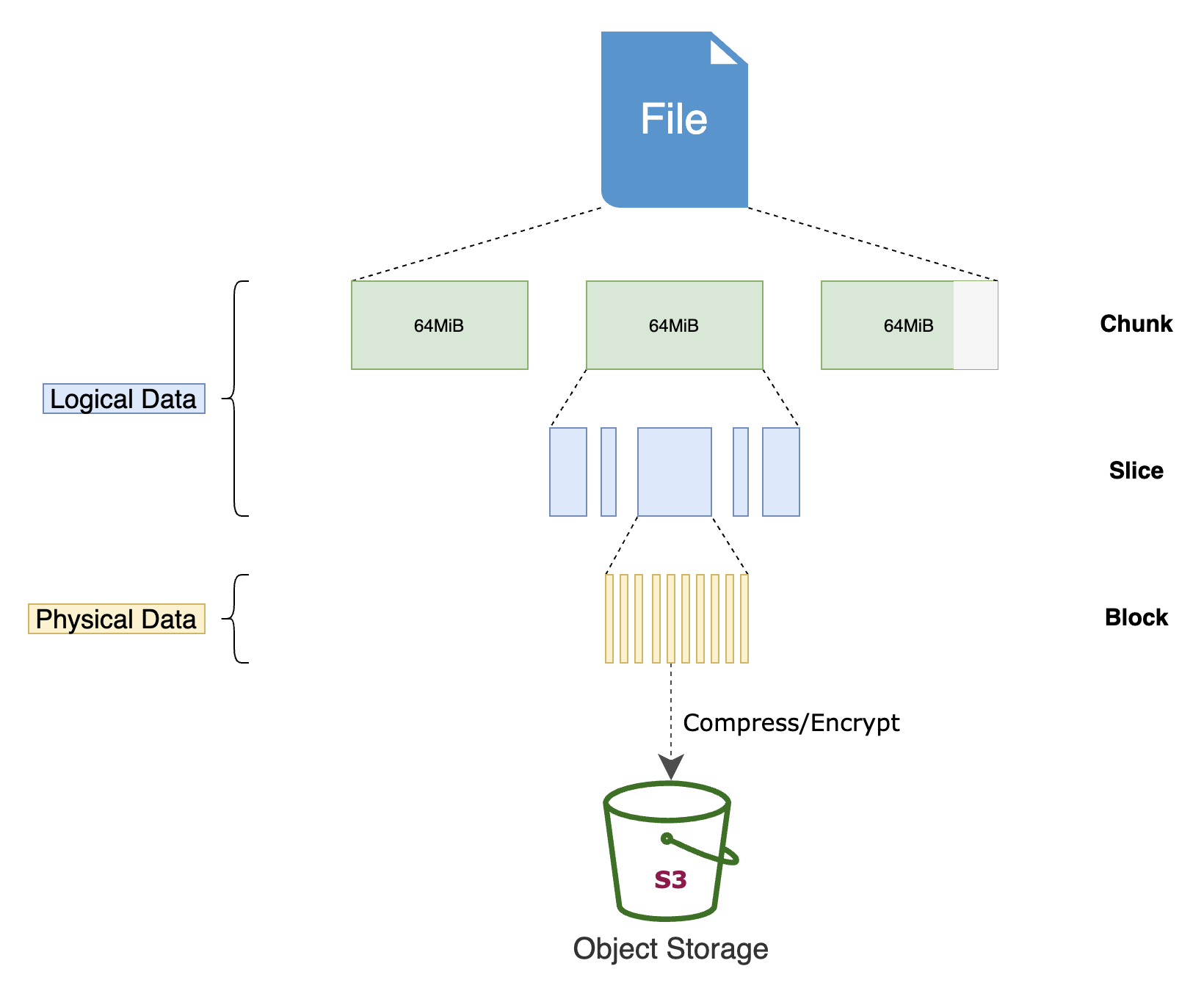
- 任何存入 JuiceFS 的文件都会被拆分成一个或多个「Chunk」(最大 64 MiB)。
- 每个 Chunk 由一个或多个「Slice」组成。
- Chunk 的存在是为了对文件做切分,优化大文件性能,Slice 则是为了进一步优化各类文件写操作,二者同为 JuiceFS 文件系统内部的逻辑概念。
- Slice 的长度不固定,取决于文件写入的方式。
- 每个 Slice 又会被进一步拆分成「Block」(默认大小上限为 4 MiB),Block 是最终上传至对象存储的最小存储单元。
因此,你会发现在对象存储平台的文件浏览器中找不到存入 JuiceFS 的源文件,存储桶中只有一个 chunks 目录和一堆数字编号的目录和文件,这正是经过 JuiceFS 拆分存储的数据块。如下图:
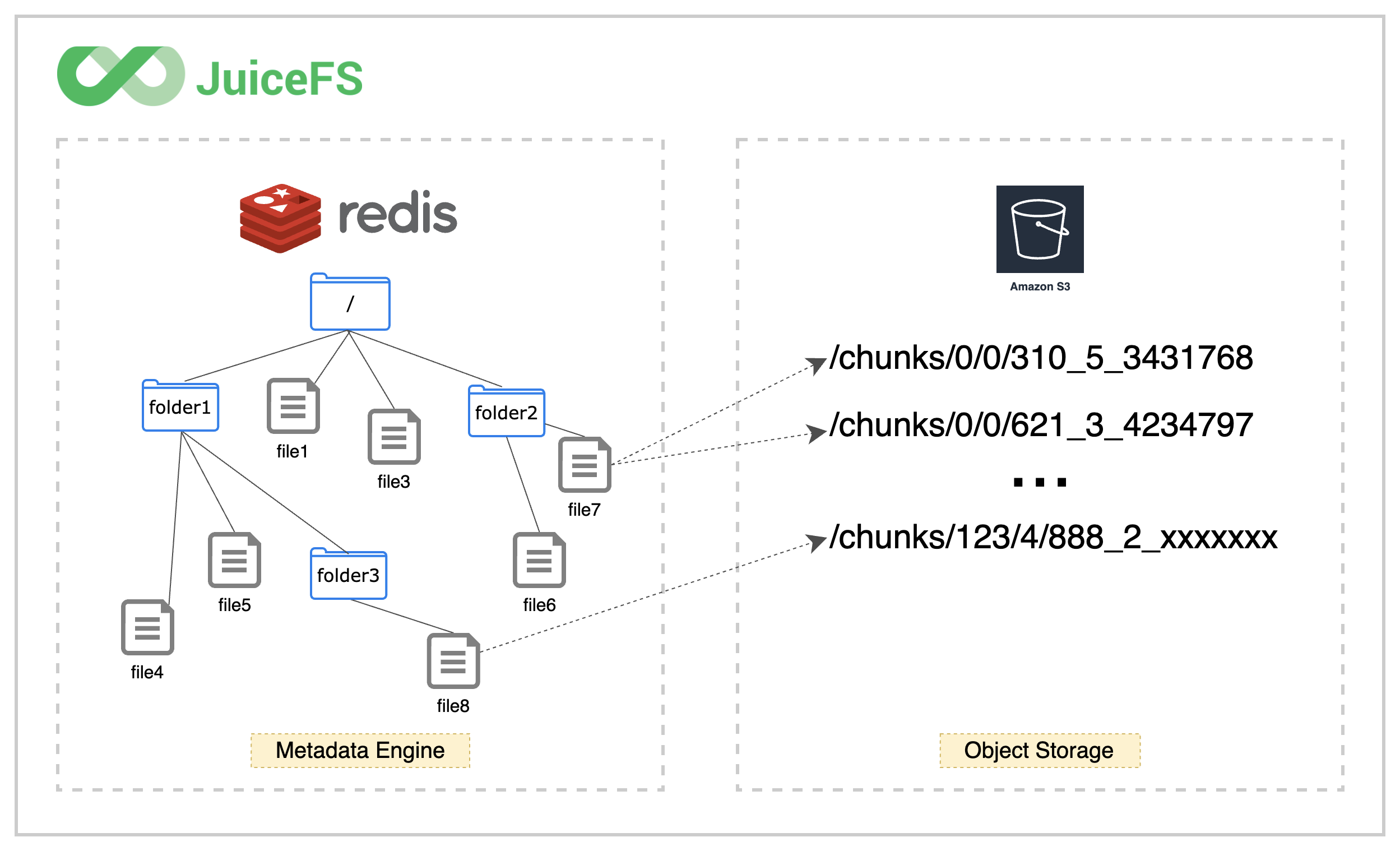
可以看到一个文件,经由 JuiceFS,到了对象村处理,就变成一个或多个 blocks 存储了,是看不出源文件长啥样子的。
与此同时,文件与 Chunks、Slices、Blocks 的对应关系等元数据信息存储被在元数据引擎中。正是这样的分离设计,让 JuiceFS 文件系统得以高性能运作。
JuiceFS 的存储设计,还有以下技术特点:
- 对于任意大小的文件,JuiceFS 都不进行合并存储,这也是为了性能考虑,避免读放大。
- 提供强一致性保证,但也可以根据场景需要与缓存功能一起调优,比如通过设置出更激进的元数据缓存,牺牲一部分一致性,换取更好的性能。
- 支持并默认开启「回收站」功能,删除文件后保留一段时间才彻底清理,最大程度避免误删文件导致事故。