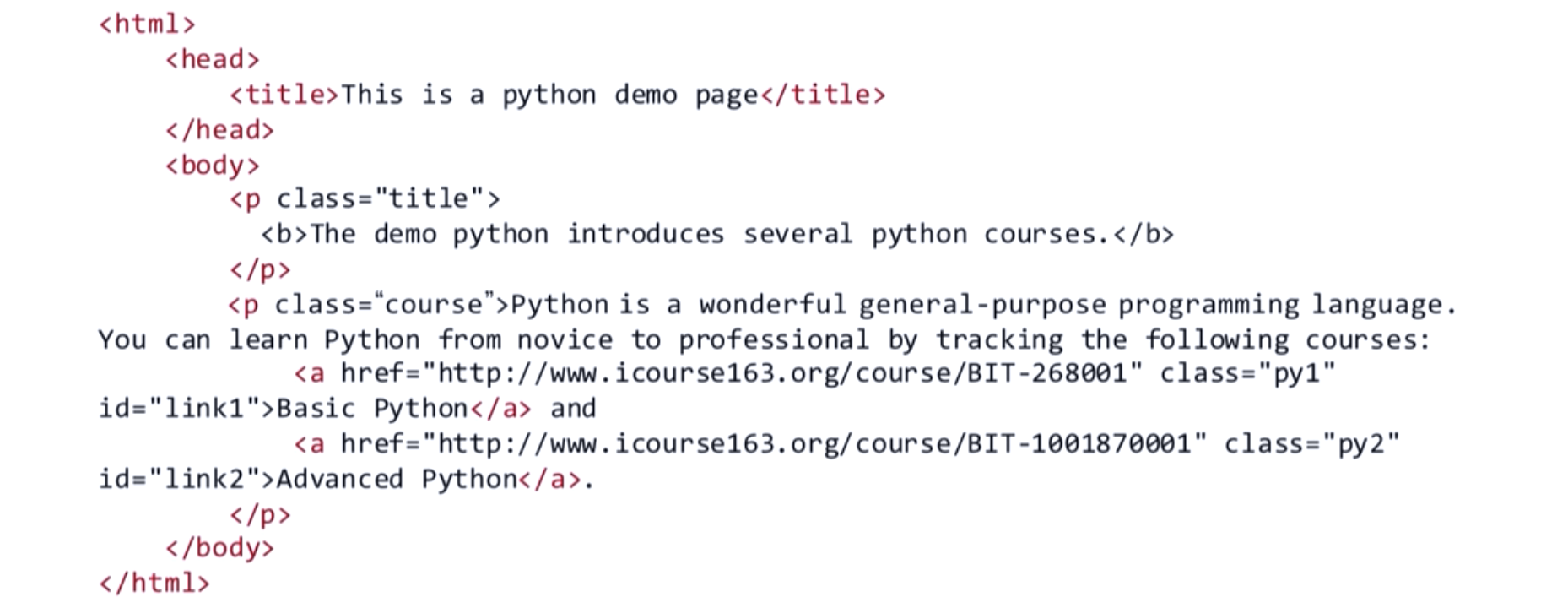
>>> import bs4 # 过滤结点代码用到了bs4.element.Tag,前面没有import >>> for child in soup.head.children: ... if(isinstance(child, bs4.element.Tag)): # 过滤字符串类型孩子结点 ... print(repr(child)) ... <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>Beautiful Soup: We called him Tortoise because he taught us.</title> <link href="mailto:leonardr@segfault.org" rev="made"/> <link href="/nb/themes/Default/nb.css" rel="stylesheet"type="text/css"/> <meta content="Beautiful Soup: a library designed for screen-scraping HTML and XML." name="Description"/> <meta content="Markov Approximation 1.4 (module: leonardr)" name="generator"/> <meta content="Leonard Richardson" name="author"/>
1 2 3 4 5 6 7 8 9 10 11
>>> for child in soup.head.descendants: ... if(child.name != None): ... print(child) ... <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>Beautiful Soup: We called him Tortoise because he taught us.</title> <link href="mailto:leonardr@segfault.org" rev="made"/> <link href="/nb/themes/Default/nb.css" rel="stylesheet"type="text/css"/> <meta content="Beautiful Soup: a library designed for screen-scraping HTML and XML." name="Description"/> <meta content="Markov Approximation 1.4 (module: leonardr)" name="generator"/> <meta content="Leonard Richardson" name="author"/>
另外注意,这里的孩子结点中既包括了标签,也包括了标签的属性、内容等信息。
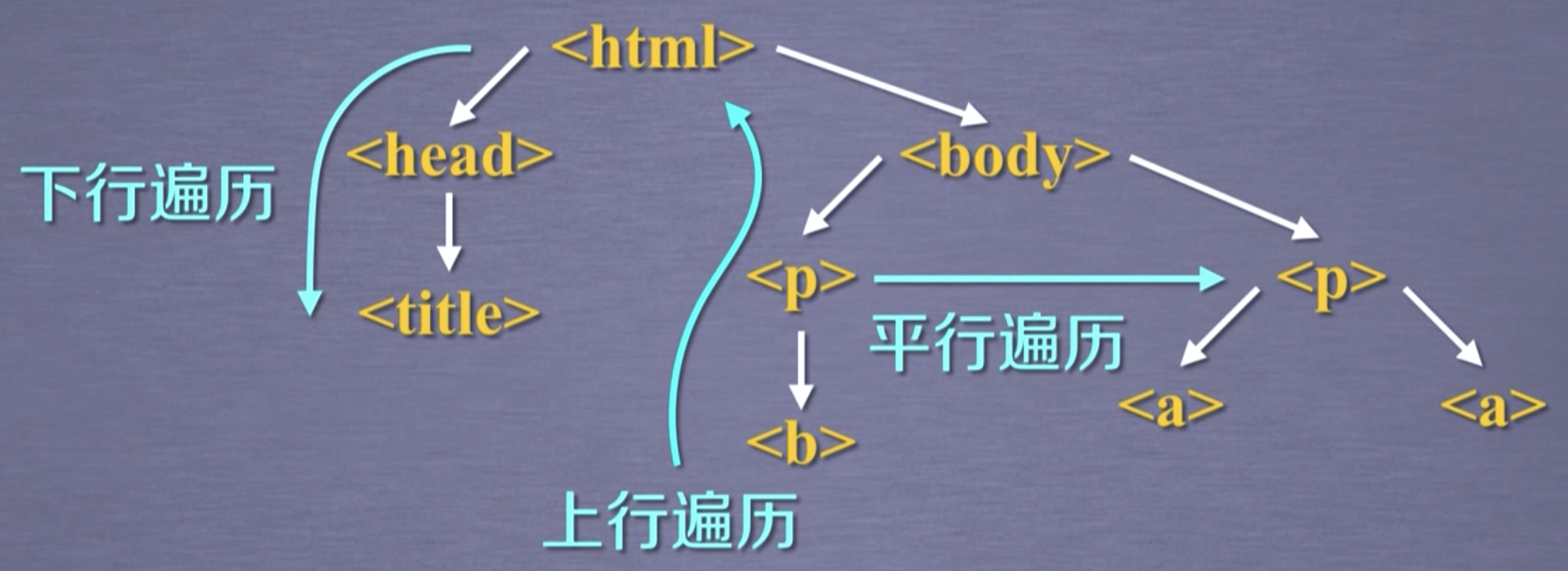
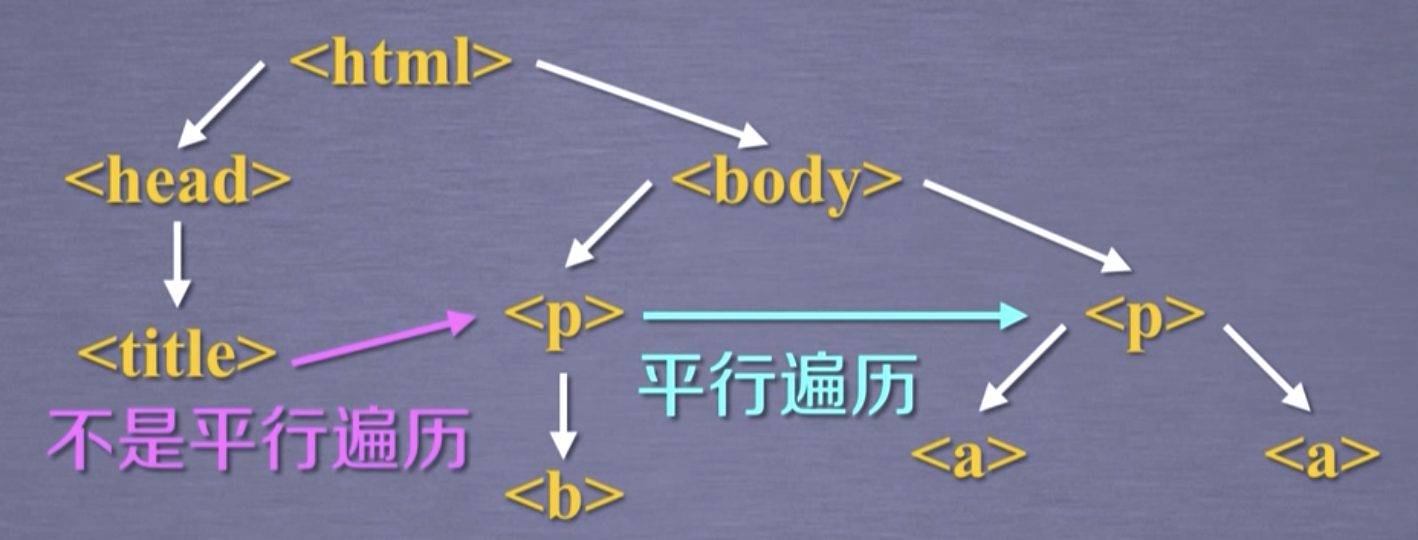
2.2. 上行遍历
标签树的下行遍历一共包含两个属性,如下。
属性
说明
.parent
结点的父亲标签。
.parents
结点先辈标签的迭代类型,用于循环遍历先辈结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
>>> soup.title.parent <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>Beautiful Soup: We called him Tortoise because he taught us.</title> <link href="mailto:leonardr@segfault.org" rev="made"/> <link href="/nb/themes/Default/nb.css" rel="stylesheet"type="text/css"/> <meta content="Beautiful Soup: a library designed for screen-scraping HTML and XML." name="Description"/> <meta content="Markov Approximation 1.4 (module: leonardr)" name="generator"/> <meta content="Leonard Richardson" name="author"/> </head> >>> soup.title.parents <generator object PageElement.parents at 0x10bfe75e8> >>> type(soup.title.parents) <class'generator'>
1 2 3 4 5
>>> for parent in soup.head.parents: # 遍历所有先辈结点 ... print(parent.name) # 先辈结点中有包括了整个文本的<html></html>标签,内容太多,这里只输出其name属性 ... html [document]